Let’s take a simple scenario: say that you’re developing a holiday request system (because the previous MS Access-cum-Excel-cum-Word jalopy that the boss wrote ten years ago has finally corrupted beyond the point of no return). You’re given the basic parameters, and then, if you’re like me, you start pseudo-coding:
class HolidayManager
{
void RequestHoliday(Employee emp, DateTime start, DateTime end)
{
// TODO: sensible error messages and basic validation stuff
if (start < DateTime.Now) throw new ArgumentOutOfRangeException();
if (end < start) throw new ArgumentOutOfRangeException();
// does the user have any holiday available?
if (database.GetHolidaysRemaining(emp) == 0)
throw new OutOfHolidayException("TODO: should we use a return code?");
// assume that this call returns us a unique ID for this holiday
var holidayId = database.AddHoliday(emp, start, end, HolidayStatus.Requested);
// tell the user
emailer.SendConfirmation(emp, start, end);
// tell their line manager
var manager = database.GetLineManager(emp);
if (manager != null) // they might be the Big Boss
emailer.SendRequestForApprovalEmail(emp, start, finish, holidayId);
else
this.ApproveHoliday(holidayId, HolidayStatus.Approved);
}
void ApproveHoliday(int id, HolidayStatus status)
{
// assume this struct has info about the holiday
var holiday = database.GetHoliday(id);
if (holiday.Status == HolidayStatus.Requested)
{
database.SetApproval(id, status);
int daysLeft = database.CalculateRemainingDays(holiday.Employee);
// send email to the requester (assume that holiday includes an email address)
emailer.SendApprovalEmail(holiday, status, daysLeft);
}
else
throw new InvalidOperationException("already approved");
}
}
What we have here is a basic sketch of our business logic – we don’t care about how the database works, and we don’t care how emails go out, because that’s not important to us at this stage.
If, whilst pseudo-coding, you find yourself writing GetStuffFromDatabase or somesortofqueue.Push(msg), then congratulations – you’ve identified your dependencies!
Whenever you find yourself writing a quick note to cover up what you know will be a complicated process (retrieving data from a store, passing messages to a queue, interacting with a third party service, etc.), then this is an excellent candidate for a dependency.
Looking at our example, we’ve got two dependencies already:
- database
- emailer
Now, my point here is not to design the best holiday application imaginable – the code above is just a sketch. My point is that we’ve now identified some application boundaries, namely the boundary between business logic and services.
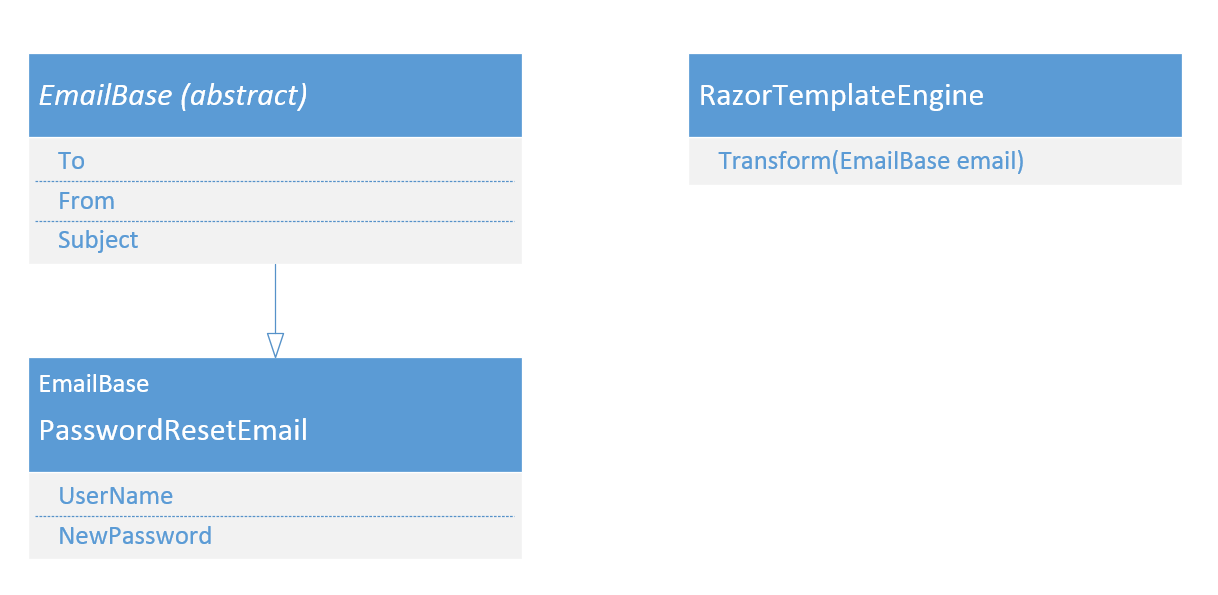
Let’s take this a little further: in our emailer implementation, we might have further dependencies. Say that our emailer implementation needs to format an email (given data and a template) and then send it. We might switch the formatter at some point in the future (using RazorEngine, NVelocity or just string.Format) and we might change the delivery mechanism (because the business now has a central email queue, and we need to submit messages to that instead of using SMTP directly). In this case, the business logic of the email engine is:
class HolidayEmailer {
IEmailFormatter formatter;
IEmailSender sender;
IEmailLogger logger;
void SendEmail(someObject email)
{
var message = new System.Net.MailMessage();
message.To.Add(email.To);
message.Subject = email.Subject;
message.Body = formatter.Format(email);
sender.Send(message);
logger.Log(message);
}
}
What this means is that we have many levels of DI – from the point of view of our holiday app, it has an abstraction that it can call to send emails, and we can unit test our object against a mock. We can also test our emailer implementation, because we’ve abstracted the formatting, sending and logging, which means that we can test what happens if any of these fail, or produce weird results.
 If code is less obvious, it takes longer for a developer to fully understand it – and the result is that developers are more likely to inadvertently break stuff because they don’t realise that the layer of smoke-and-mirrors is pretending that it’s something else to satisfy the needs of an old bit of VB6. In effect, we’re disguising complexity, and thus we create elephant traps.
If code is less obvious, it takes longer for a developer to fully understand it – and the result is that developers are more likely to inadvertently break stuff because they don’t realise that the layer of smoke-and-mirrors is pretending that it’s something else to satisfy the needs of an old bit of VB6. In effect, we’re disguising complexity, and thus we create elephant traps.